为了自动从科学论文中捕获重要数据,美国国家标准技术研究院(NIST)的计算机科学家开发了一种方法,可以在图像数据中包含的密集,低质量绘图中准确检测小的几何对象,例如三角形。NIST模型采用旨在检测模式的神经网络方法,在现代生活中具有许多可能的应用。
NIST的神经网络模型在一组定义的测试图像中捕获了97%的对象,并将对象的中心定位在手动选择位置的几个像素内。
NIST的计算机科学家Adele Peskin解释说:“该项目的目的是恢复期刊文章中丢失的数据。” “但是,小型密集物体检测的研究还有很多其他应用。物体检测被广泛用于图像分析,自动驾驶汽车,机器检查等领域,而小型密集物体的检测尤其困难。找到并分开。”
研究人员从NIST的热力学研究中心(TRC)的金属特性数据库中获取了可追溯到1900年代初的期刊文章的数据。通常,结果仅以图形格式显示,有时是手工绘制,而由于扫描或影印而退化。研究人员希望提取数据点的位置,以恢复原始的原始数据,以进行进一步的分析。到目前为止,这些数据都是手动提取的。
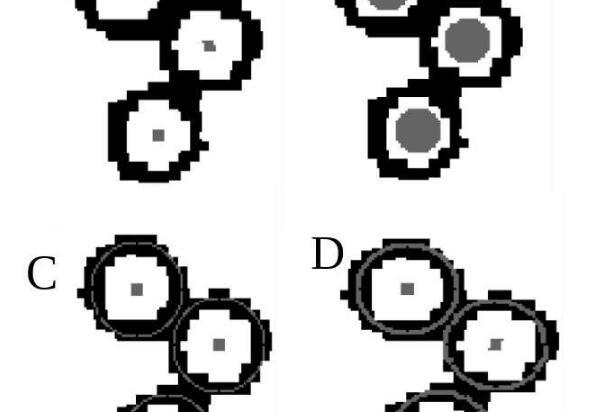
图像为数据点提供了各种不同的标记,主要是圆形,三角形和正方形(实心和实心),具有不同的大小和清晰度。这种几何标记通常用于标记科学图中的数据。在训练神经网络之前,使用图形编辑软件从文本的子集中手动删除了可能会错误地显示为数据点的文本,数字和其他符号。
由于多种原因,准确检测和定位数据标记是一个挑战。标记的清晰度和确切形状不一致;它们可能是开放的或充满的,有时是模糊的或失真的。例如,某些圆形看起来非常圆形,而其他圆形则没有足够的像素来完全定义其形状。另外,许多图像包含非常密集的重叠圆,正方形和三角形的补丁。
研究人员试图创建一种网络模型,以至少与手动检测一样准确地识别出绘图点-在绘图实际位置的五个像素之内,每侧大小为数千个像素。
如一篇新的期刊论文所述,NIST研究人员采用了最初由德国研究人员开发的用于分析生物医学图像的网络架构,称为U-Net。首先缩小图像尺寸以减少空间信息,然后添加要素和上下文信息层以建立精确的高分辨率结果。
为了帮助训练网络对标记形状进行分类并确定其中心,研究人员尝试了四种使用蒙版标记训练数据的方法,即为每个几何对象使用不同大小的中心标记和轮廓。
研究人员发现,向蒙版添加更多信息(例如,更粗的轮廓)可以提高对物体形状进行分类的准确性,但可以降低在图中确定其位置的准确性。最后,研究人员结合了几种模型的最佳方面,以获得最佳分类和最小的位置误差。事实证明,更改掩码是提高网络性能的最佳方法,它比其他方法(例如在网络末端进行小的更改)更有效。
网络的最佳性能-定位对象中心的精度达到97%-仅对于图像点的子集是可能的,在这些图像中,绘图点最初由非常清晰的圆形,三角形和正方形表示。对于TRC而言,其性能足够好,可以使用神经网络从较新的期刊论文中从图中恢复数据。
尽管NIST研究人员目前没有后续研究计划,但神经网络模型 “绝对”可以应用于其他图像分析问题,Peskin说。















