量子信息科学家介绍了一种用于量子计算中机器学习分类的新方法。量子二元分类器中的非线性量子内核为提高量子机器学习的准确性提供了新的见解,被认为能够胜过当前的AI技术。
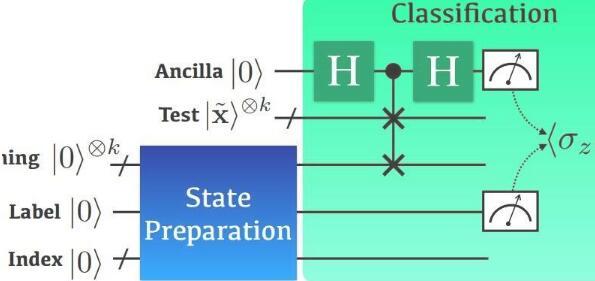
由电气工程学院的June-Koo Kevin Rhee教授领导的研究小组提出了一种基于量子态保真度的量子分类器,该量子分类器使用了不同的初始状态并将Hadamard分类替换为交换测试。与常规方法不同,该方法有望在训练数据集较小时通过利用在大特征空间中发现非线性特征的量子优势来显着增强分类任务。
量子机器学习有望成为量子计算的必不可少的应用之一。在机器学习中,广泛应用的一个基本问题是分类,这是识别带标签的训练数据中的模式以便将标签分配给以前未见过的新数据的任务。核方法已经成为识别复杂数据中非线性关系的宝贵分类工具。
最近,内核方法已成功引入量子机器学习。量子计算机有效访问和处理量子特征空间中数据的能力可以为量子技术打开机会,以增强各种现有的机器学习方法。
带有非线性核的分类算法的思想是,在给定量子测试状态的情况下,协议通过交换测试电路并随后进行两个单量子位测量来计算量子并行中量子数据的保真度的加权功率和(参见图2)。 1)。无论数据大小如何,这仅需要少量的量子数据操作。这种方法的新颖性在于,可以将标记的训练数据密集地打包成量子状态,然后与测试数据进行比较。
KAIST团队与南非夸祖鲁-纳塔尔大学(UKZN)和德国数据控制论的研究人员合作,通过引入具有量身定制的量子核的量子分类器,进一步推进了快速发展的量子机器学习领域。
输入数据可以通过量子特征图由经典数据表示,也可以由固有量子数据表示,并且分类基于核函数,该核函数测量测试数据与训练数据的接近度。
这项研究的主要作者之一,KAIST的Daniel Park博士说,量子核可以系统地定制为任意功率之和,这使其成为现实应用的极佳候选者。
Rhee教授说,量子分叉是团队先前发明的一种技术,即使所有标记的训练数据和测试数据都独立编码在单独的qubit中,它也可以从头开始协议。
UKZN的Francesco Petruccione教授解释说:“两个量子态的状态保真度包括概率振幅的虚部,从而可以利用整个量子特征空间。”
为了证明分类协议的有效性,Data Cybernetics的Carsten Blank实施了分类器,并使用五位数的IBM量子计算机(通过云服务免费提供给公共用户)比较了经典模拟。“这是该领域正在发展的一个有希望的信号,”布兰克指出。















